之前在寫pwn的筆記時,一直很猶豫要不要把x86的call convention(呼叫約定)特別拿出來講
畢竟這是pwn的基礎,像是overflow和rop都需要這個觀念,但是網路找不到一個對此
有很通篇透徹的解說,剛好最近也研究出一個結果了決定po一篇作紀錄
個人覺得寫得還不錯 說不定看完上面這兩篇大家都懂了也不需要我在寫這一篇了
其中Stack Frame就是我們這次的主題(個人覺得call convention其實就是暫存器與stack之間的互動)
Stack Frame
Stack Frame 就是程式在記憶體內執行的一個區間
每一個function執行前都會先畫一個Stack Frame
那Stack Frame是做什麼用的呢?是拿來存放一些區域變數(之類的)需要的空間
講Stack Frame之前要先認識兩個暫存器
esp: 指向Stack內最後一個push(pop)的位置
ebp: 指向Stack Frame的最上面位置
ebp到esp的這個位置區間我們稱之為Stack Frame
一個正常的x86 Stack Frame 有下列的特徵:
1 | ebp -> 上一個ebp存的 address |
為什麼要用ebp來當基準,而不用esp呢?
因為esp每push(pop)一個值 esp 指向的的位置就會-(+)4
隨著push(pop)的值越多就必須讓esp-(+)越多的值才能得到參數的位置
相較於esp,ebp就是一直指著記憶體頂端,相對static
當初出現ebp的理由好像也是讓CPU讀取變數位置能夠更加方便
至於 push 和 pop 的詳細運作情況是怎麼樣呢?1
2
3
4
5push reg <= same as => sub esp, 4 # subtract 4 from esp
mov esp, reg # store, using esp as the address
pop reg <= same as=> mov reg, esp # load, using esp as the address
add esp, 4 # add 4 to the esp
同場加映 call 的詳細運作
1 | push eip |
這邊用C語言粗略的講一下Stack Frame
這是source code:
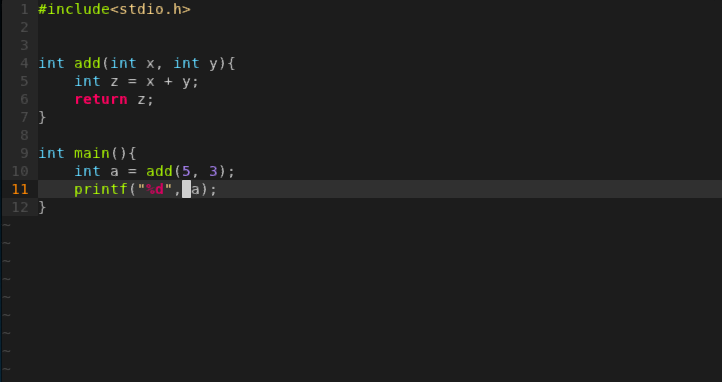
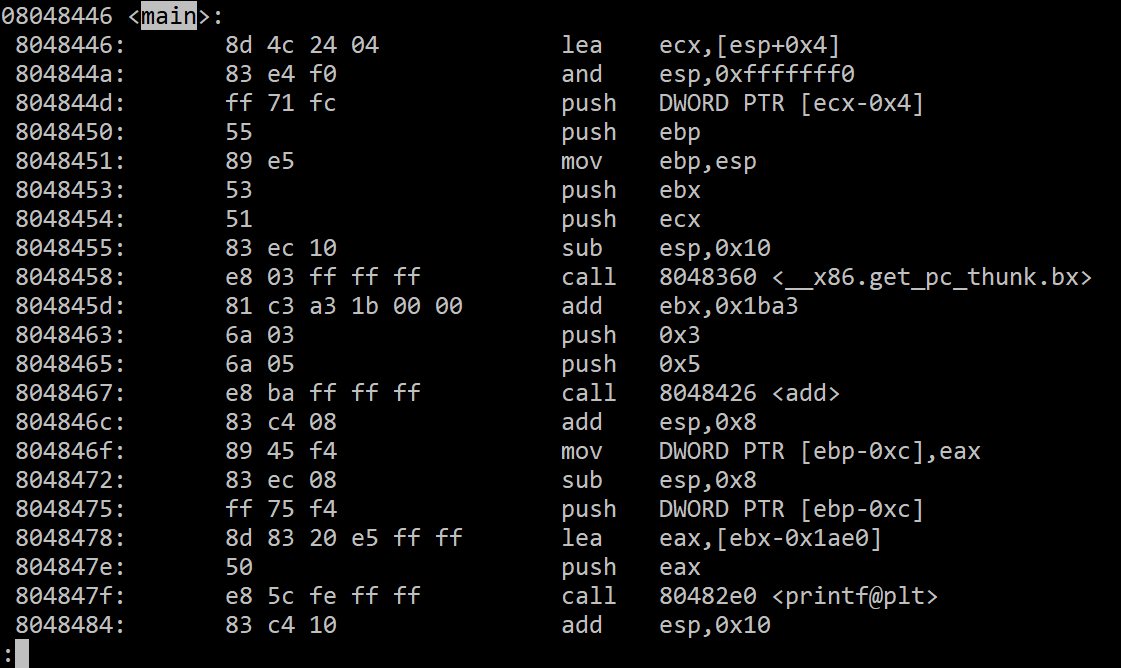
這是main function的組合語言:
這是add function的組合語言:
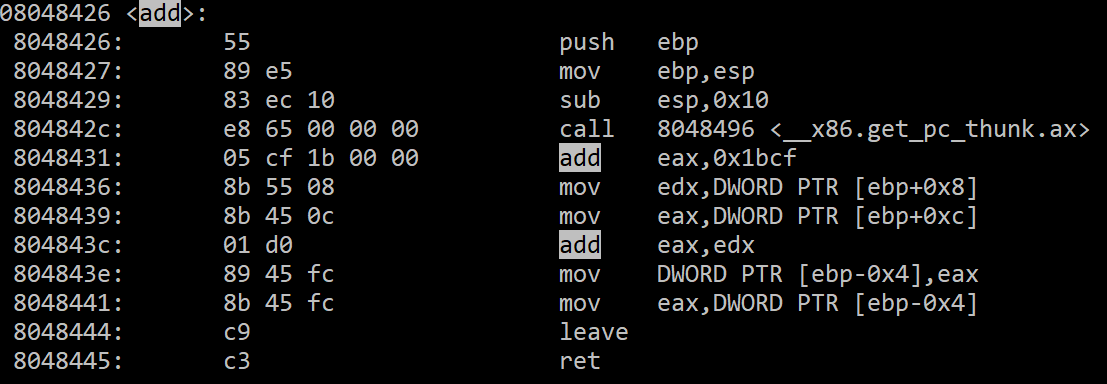
現在說明add function是如何劃出一個Stack Frame的
第一行我們先push ebp,把ebp現在的address(也就是main的ebp address)
存進stack內
第二行是把esp的address(就是main 的esp address-4)放進ebp內取得return address
這邊筆記一下─ 所以現在的ebp address + 4 = main的esp address
(因為前面push ebp導致esp-4)
第三步是拉出function需要使用的stack範圍大小(esp-n, n取決於function需要的大小)
這是call function的前置步驟
下面的leave其實就只是把上面的前兩條指令倒回去而已
mov esp,ebp
pop ebp
再細一點
mov esp,ebp
mov ebp,esp
add esp,4
mov esp,ebp就是把esp跟ebp的address對齊(即程式執行結束後把Stack Frame歸0)
然後把ebp pop出去(回到之前main的ebp address)
這個動作會順便把esp+4,補足最上面push ebp造成的esp-4
最後的ret其實就是pop eip
再細一點就是執行這兩個步驟
mov eip,[esp]
add esp,4
把esp指向的address(也就是main的esp address)先丟給EIP,esp自己再+4(因為是pop阿)
讓add function結束後能回到main function中斷的地方繼續執行
以上就是main function呼叫add function的流程,最後用一張圖結尾
而Stack overflow 就是能控制return address要去什麼地方,
可以跳到任何我們想要的地方執行shellcode或是跳到我們想要的函示庫(ex.libc.so)
先有這個概念之後再看Lays大大的ROP輕鬆談會比較友善點…
最後附上參考資料:
ROP輕鬆談:
https://www.slideshare.net/hackstuff/rop-40525248
NTUSTISC - Pwn Basic II [2018.05.10]
https://www.youtube.com/watch?v=I7qCc0Xuhdc&feature=youtu.be
What is the function of the push / pop instructions used on registers in x86 assembly?
https://stackoverflow.com/questions/4584089/what-is-the-function-of-the-push-pop-instructions-used-on-registers-in-x86-ass
x64 version
寫windows的筆記後覺得應該回過頭來補一下 x64 的呼叫約定
x64因為暫存器與記憶體空間變大了,所以前6個argv會存在 register裡面
依序是 rdi rsi rdx rcx r8 r9 第七個開始才會放入stack內
來個範例:
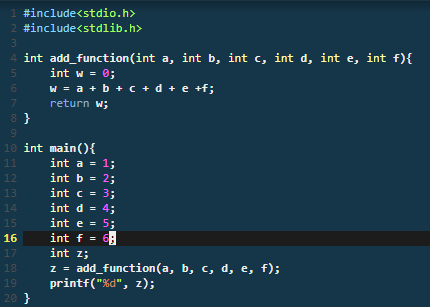
在objdump裡面就是長這樣子
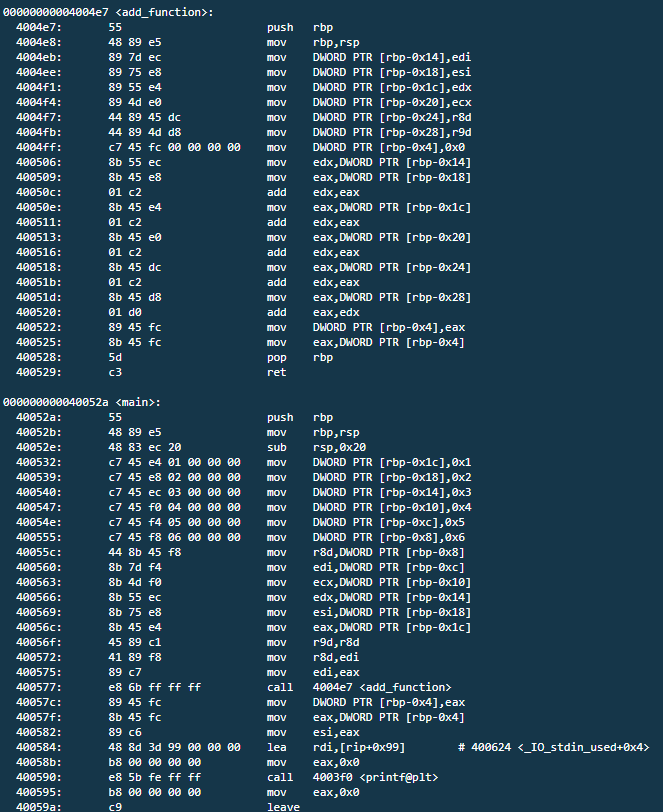
當buufer overflow的時候比起x86需要多找能更改 register 內部的值的 assambly (ex: pop rdi)
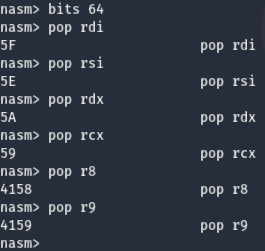
基本上要找相關的 assambly 是直接找 opcode 最快
這部分可以交給 nasmshell 做到
https://github.com/fishstiqz/nasmshell
服用前記得,要 python3 並且已經 apt install nasm (採過坑的路過), metasploit 好像也有,但我不習慣用那個
這邊大概列一下給大家,我自己常找的opcode
ARM version
最近因為工作因素,在更新一版 ARM 的
ARM 的環境是用 dockerpi 建的
soruce code: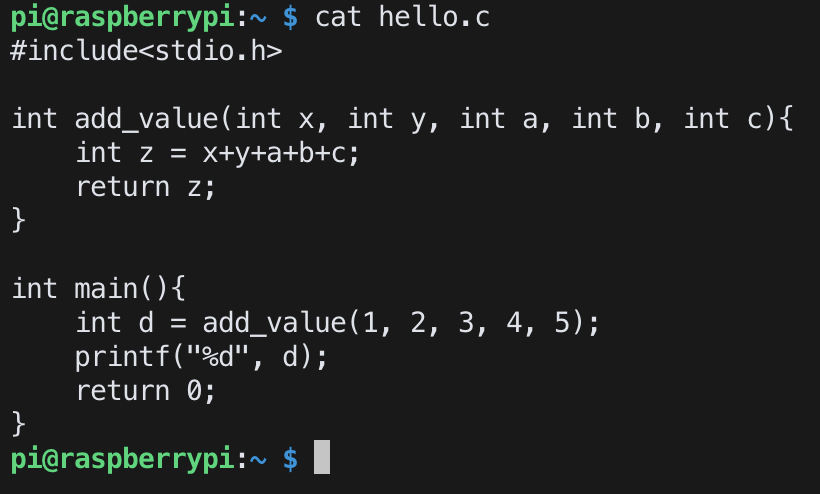
main: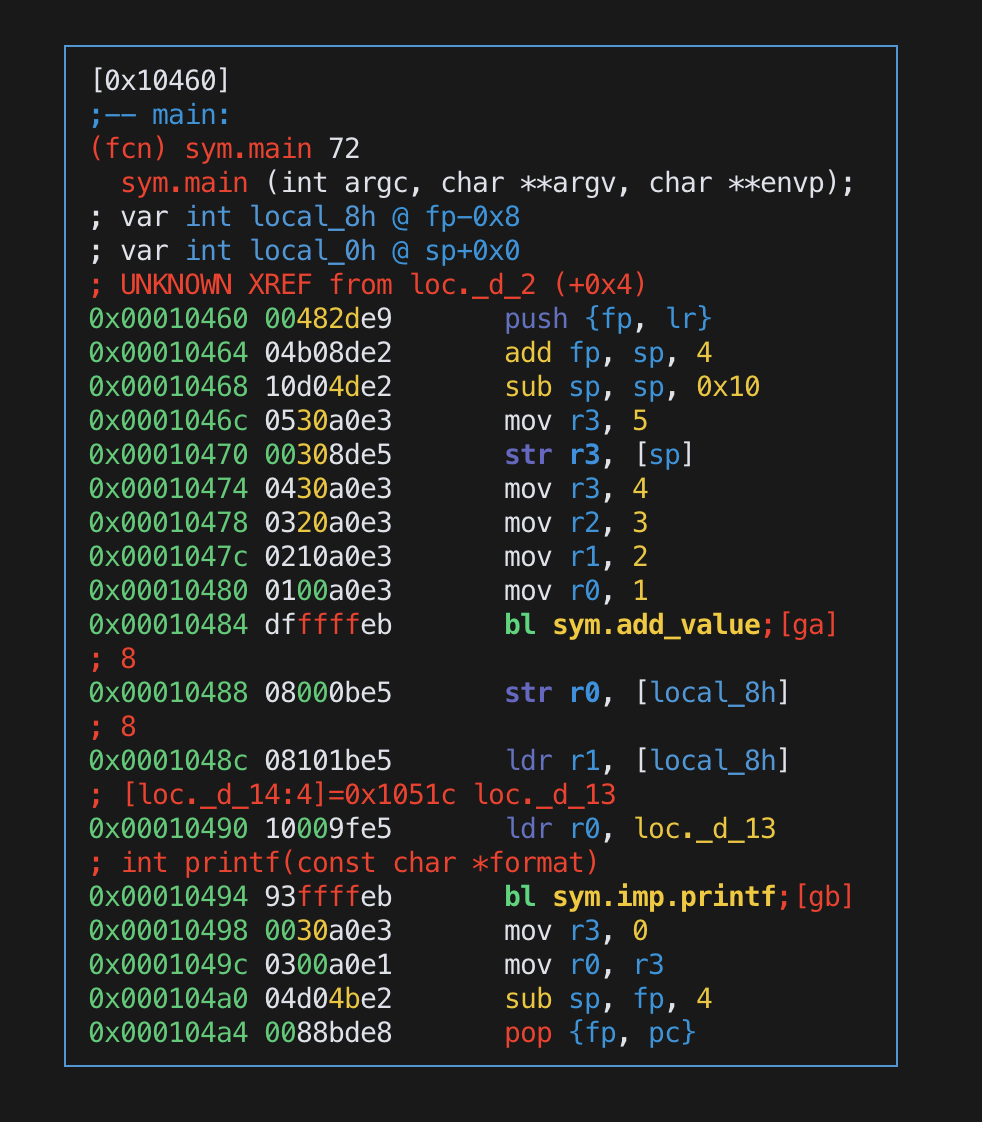
其實還是跟 x86 有些許不一樣的地方,但這些不一樣的地方可能就會導致 exploit 失敗
主要的差別在於,x86 的 call 指定是將 EIP+0x4 or RIP+0x8 push 到 stack 內再做跳轉,然後 x86 的 BP 指向的位址存放著舊的 BP 位址
但 arm 的 bl 是將下一個指令的位置放到 lr 暫存器內,在跳過去,然後 push {fp, lr} 的順序是 先 push lr 再 push fp在下一條指令 add fp, sp, 4 是 fp = sp+0x4,因此做完後 fp 其實會指向 lr,也就是 return address,然後在最下面的 sub sp, fp ,4,是將 sp 指向舊的 fp 位置,然後 pop {fp, pc} 是先 pop stack 最上面的位置的值,也就是舊的 fp 位置,pop 到 fp,再將 lr 的位置 pop 到 pc
所以在做 buffer overflow 的時候,算 offset 的時候要看 r11 的位置,把 r11 的位置蓋掉後最後 pop 才會正確的 pop 到 pc
add_value: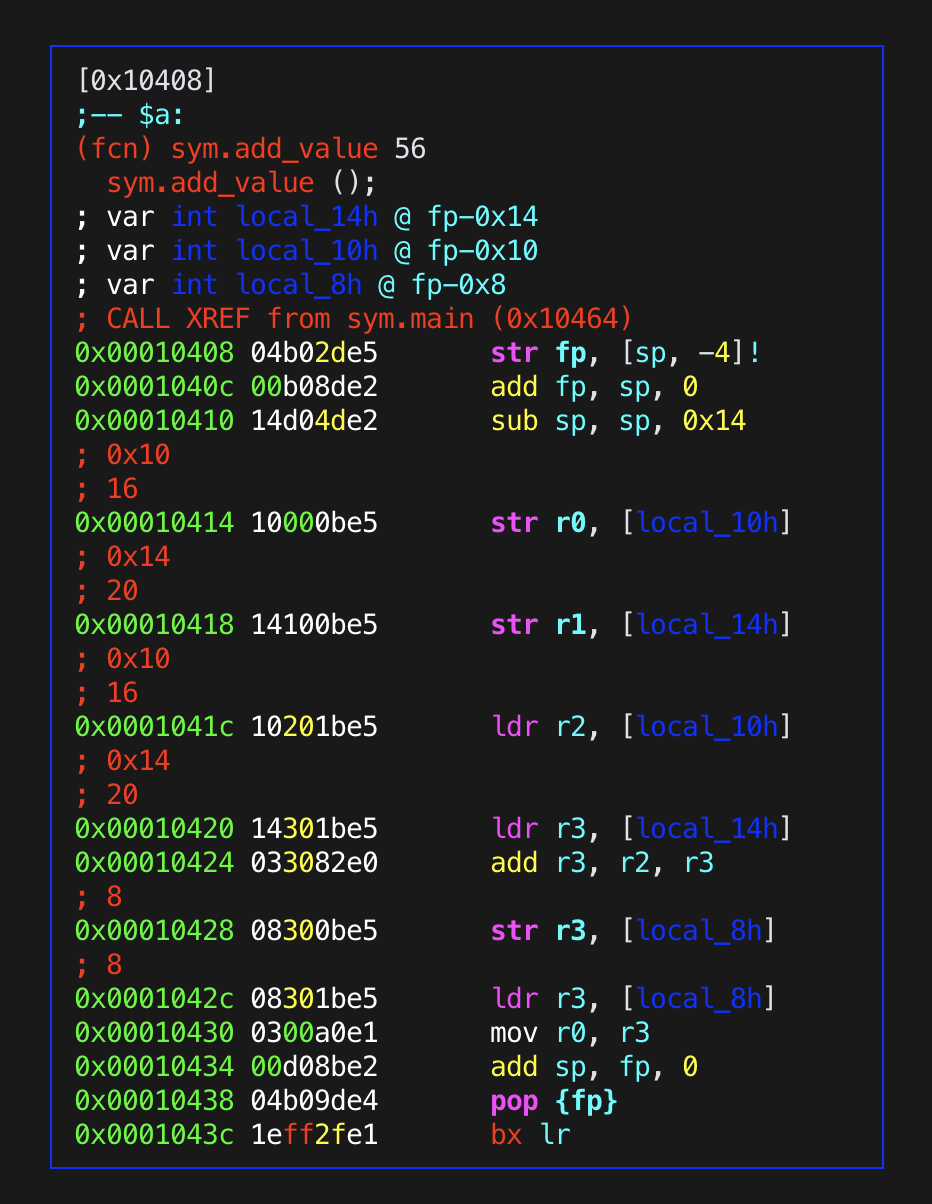
其實還是跟 x86 有些許不一樣的地方,但這些不一樣的地方可能就會導致 exploit 失敗
主要是,